






Google Colaboratory(通称:Google Colab)は、今日のデータサイエンスとAI分野で非常に便利なツールとなっています。
そのため、私たちの今回の目標は、あなたにGoogle Colabの魅力を伝え、その基本的な使い方を伝授することです。この記事を読めば、初心者でも自信を持ってGoogle Colabを活用できるものとなっているでしょう。
Google Colaboratoryとは
Google ColabはGoogleが提供するクラウドベースのPython開発環境です。Google Colabを使えば、ブラウザさえあればどこでもコードを書き、実行することができます。
Google Colabは、Pythonのコードを書くための「コードセル」や説明文を書くための「テキストセル」を用意しており、それらを組み合わせてノートブックと呼ばれる一連の作業内容を作成します。コードセルとテキストセルについては後ほど詳しく説明します。
Google Colaboratoryの特徴
それではGoogle Colabの特徴を見ていきましょう。
環境構築が不要なPython記述環境
Google Colabの一番の特徴は、Python環境のセットアップが必要ないという点です。自分のコンピュータにPythonや関連ライブラリをインストールする手間を省くことができます。これにより、Pythonのプログラミングに集中することができます。
ハイスペックの環境が無料で利用できる
Google Colabでは、無料でGPUやTPU(Tensor Processing Unit)を利用することができます。これらの高性能ハードウェアは、深層学習のような計算量の多いタスクを効率的に行うのに非常に役立ちます。一般利用のPCではこれらの高性能な機械学習の実装環境を実現するのは難しいのですが、Google Colabは無償でこのような高スペックの環境で分析ができるのです。
Googleサービスとの連携
Google Colabは、Google DriveやGoogle Sheetsなど他のGoogleサービスと直接連携できます。これにより、Google Drive上のデータを直接読み込んだり、ノートブックをGoogle Drive上で共有したりすることが可能になります。
Google Colabを使ってみよう
では、具体的にGoogle Colabを使ってみましょう。Google Colabでは主に「ノートブック」という形式で作業を進めます。「ノートブック」は「コードセル」及び「テキストセル」で構成されます。
まずはGoogle Colabにアクセスしてください。
ノートブックの作成
Google Colabで新しいノートブックを作成するには、Google Colabのトップページから「新しいノートブック」をクリックします。これにより新しいノートブックが作成され、自動的に新しいタブが開きます。
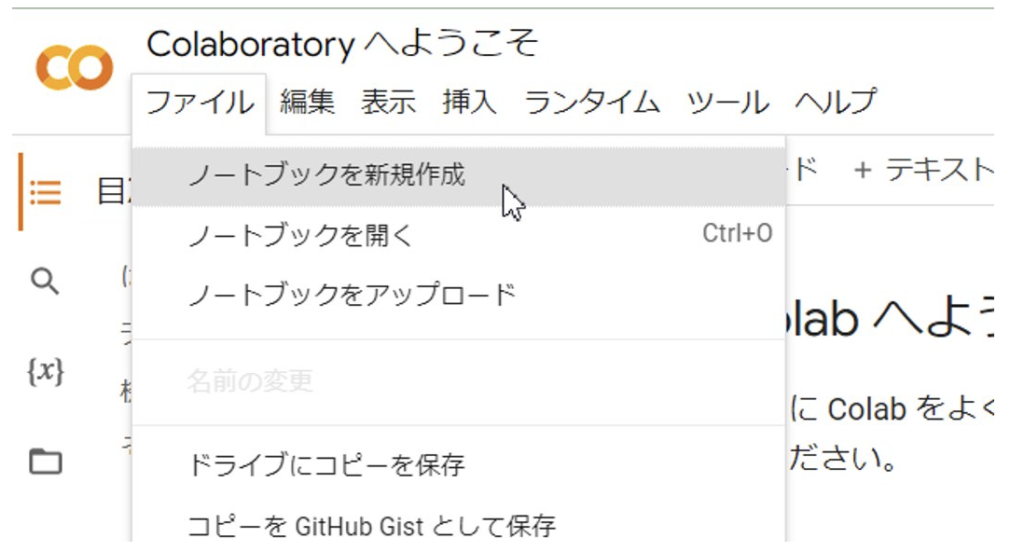
GPUやTPUの設定
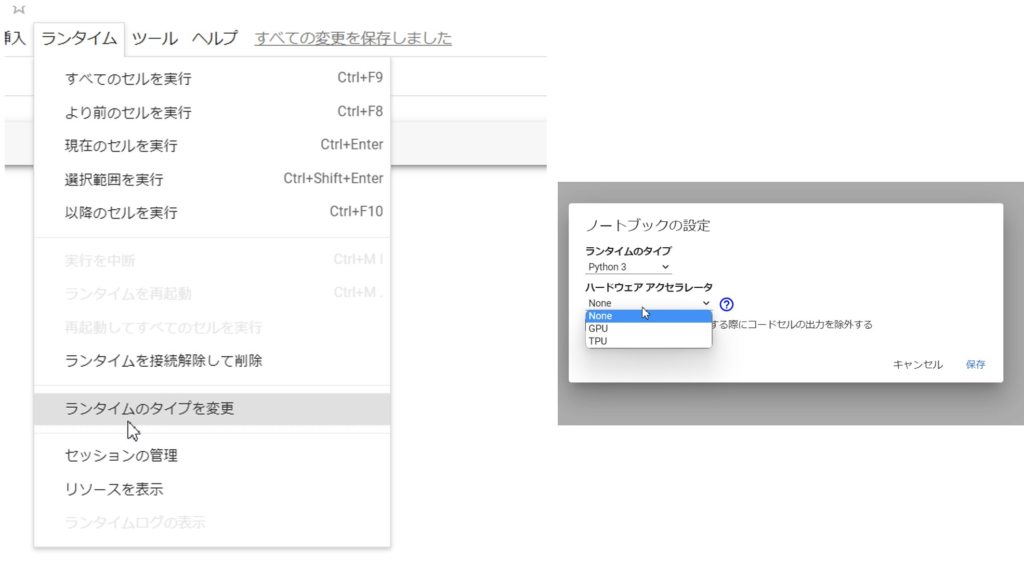
Google ColabでGPUやTPUを使うには、「ランタイム」メニューから「ランタイムのタイプを変更」を選択します。そして、ハードウェアアクセラレータとして「GPU」または「TPU」を選択ください。これにより、ノートブックはこれらの高性能な環境を使用するように設定されます。こちらの変更は任意のため、特に処理の実行スピードが気にならない場合は変更する必要はありません。画像解析など高負荷な処理を行う場合はGPUやTPUの選択を推奨します。
コードセルの書き方
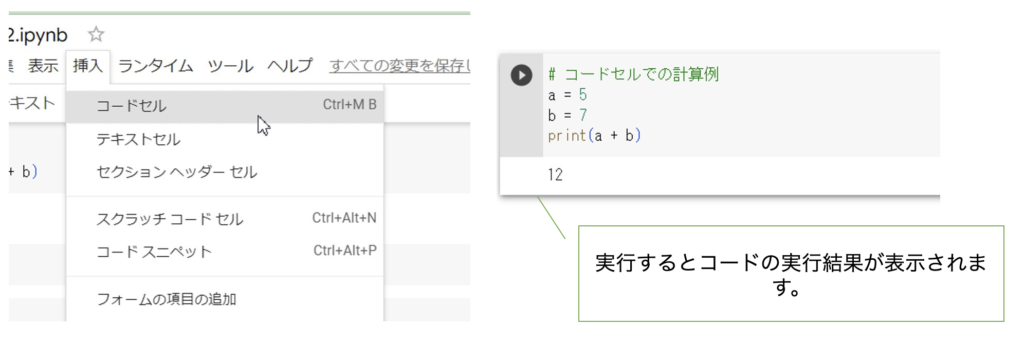
コードセルとは、Pythonのコードを記述し、実行するための領域です。新しいコードセルを追加するには、画面上部の「+ コード」をクリックします。そこにPythonのコードを書き、Shift+Enterキーを押すと、そのコードが実行されます。
例えば、簡単な計算をするコードを書いてみましょう。
# コードセルでの計算例
a = 5
b = 7
print(a + b)
このコードは、変数aとbの和を計算し、その結果を出力します。このようにコードセルを使うと、Pythonのコードを簡単に実行できます。
テキストセルの書き方
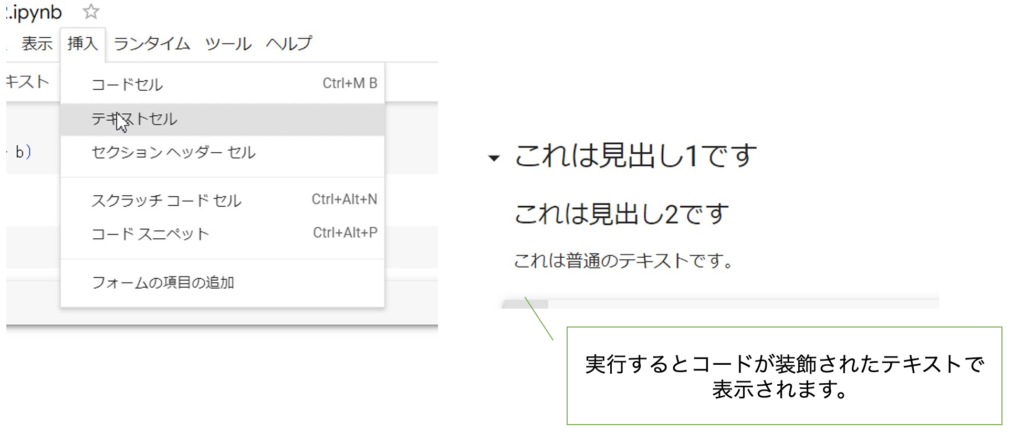
テキストセルとは、説明文やメモを記述するための領域です。新しいテキストセルを追加するには、画面上部の「+ テキスト」をクリックします。Markdown形式でテキストを記述することができます。
例えば、以下のようにテキストを記述できます。
# これは見出し1です
## これは見出し2です
これは普通のテキストです。
– これはリストです
– リストはこのように記述できます
このようにテキストセルを使うと、コードの説明などを簡単に記述できます。
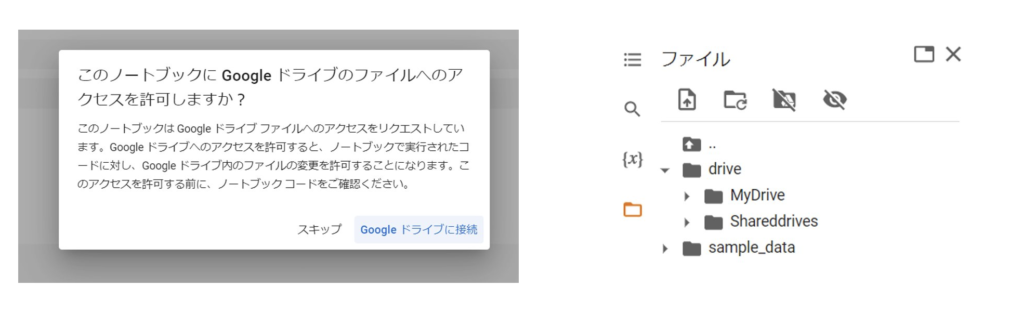
ファイルの取り込み方法
Google ColabにはGoogle Driveからファイルを直接取り込む機能があります。これにより、大量のデータを扱うときでも簡単にアクセスできます。Google Driveに接続するには以下のコードをコードセルで実行しましょう。
# Google Driveをマウントします
from google.colab import drive
drive.mount('/content/drive')
これにより、Google Driveのファイルにアクセスすることが可能になります。接続したファイルは左側のメニューからも扱えます。
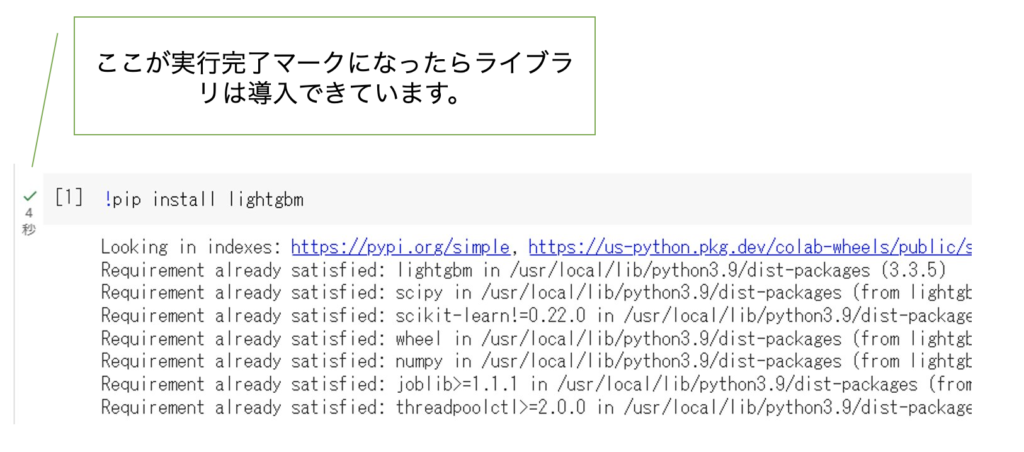
ライブラリのインストール方法
Pythonの分析にはライブラリ、という事前にだれかが作成して公開しているツールをよく利用します。ライブラリを利用することにより、本来であれば実装が非常に困難な機械学習の機能も、たった一行のコードで呼び出して利用することが出来るのです。必要なPythonライブラリはpipという命令文を使用して簡単にインストールできます。コードセルに !pip install ライブラリ名と入力し、Shift+Enterキーを押すとそのライブラリがインストールされます。
例えば、以下のようにLightGBMというライブラリをインストールします。Light GBMは高度な将来予測用の機械学習のライブラリです。この一行だけでそのような高度な機能を自身のプログラムで利用することが出来るようになるのです。
!pip install lightgbm
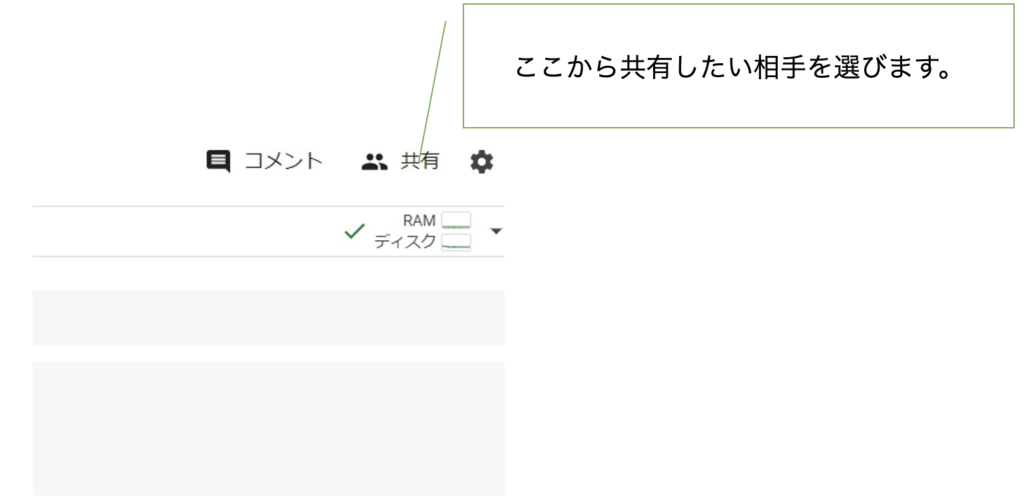
ノートブックの共有方法
Google ColabのノートブックはGoogle Drive上に保存されるため、Googleドキュメントと同様に共有することが可能です。「共有」ボタンをクリックすると共有設定画面が表示され、特定のユーザーと共有するか、リンクを通じて誰でもアクセスできるように設定することができます。
Google Colabで実際に分析をやってみよう
それでは、ここまでご説明した知識を用いて実際にデータを予測するモデルを作成してみましょう。
必要なライブラリのインストール
今回の分析にはpandas, numpy, Light GBMの3つのライブラリを利用します。PandasはPythonのプログラム上でデータの取り扱いを簡単にする機能がまとまったとてもよく利用するライブラリです。Numpyも偏差値などを計算する、など統計手法で利用する関数などがまとまったライブラリでとてもよく利用するものです。
以下のコードを実行しましょう。
!pip install pandas numpy lightgbm
ライブラリの呼び出しとデータの取得
次に先ほどインストールしたライブラリを呼び出します。ライブラリは利用する際は必ず呼び出してから利用する必要があります。呼び出しはimport という命令を使います。またfrom ライブラリ import xxxxという命令でライブラリ内の一部機能だけを呼び出すことも可能です。
ここではサンプルデータとしてGoogle Colabに含まれているサンプルデータセットであるカリフォルニアの住宅価格データを読み込みます。築年数や部屋数などの情報と価格(10万米ドル単位)の物件データが入っているデータセットです。これらをデータフレーム、という分析用のデータの入れ物に入れた後に中身を出力してみます。
以下を張り付けて実行してみましょう。画像のような結果が出れば成功です。Targetが今回予測する物件価格の項目です。
# 必要なライブラリをインポートします
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from lightgbm import LGBMRegressor
# サンプルデータセット(カリフォルニアの住宅価格データ)を読み込みます
from sklearn.datasets import fetch_california_housing
california = fetch_california_housing()
# データフレームに変換します
df = pd.DataFrame(california.data, columns=california.feature_names)
df['Target'] = california.target
# データフレームを出力します
df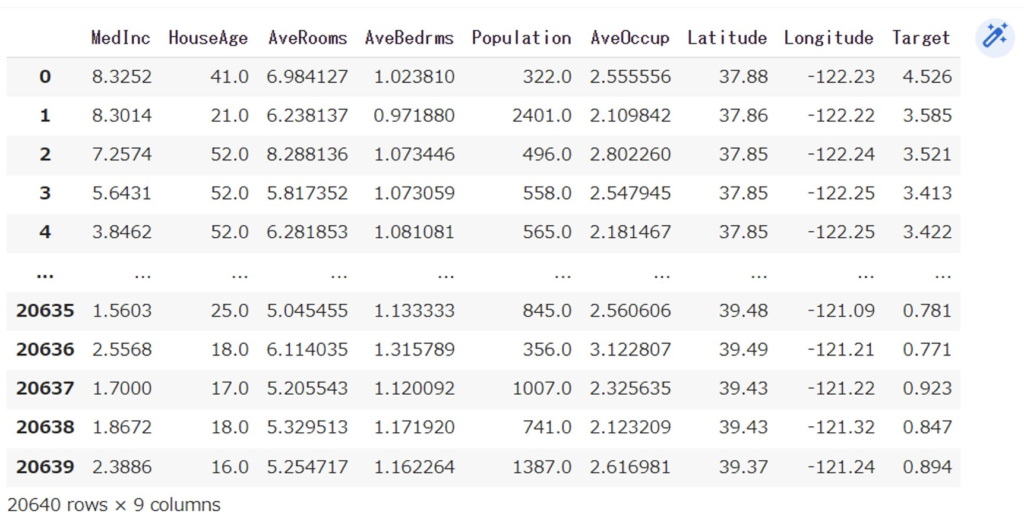
データフレームの分割と学習モデルの作成
次にデータフレームを学習データとテストデータの二つに分割します。基本的に機械学習を進める際は予測モデルを作成するための学習データと作成したモデルを評価するためのテストデータの二つに事前にデータを分割しておきます。一般的には8対2に分けることが多いです。要は8割のデータで作った予測モデル(=予測式)を使って残り2割のデータの予測値を出してみて、実際のデータと比較することで予測モデルの精度を算出するという流れになります。
予測モデルはLight GBMというライブラリを用います。とても精度の高い予測モデルを生成できるライブラリで、たった以下のコードを書くだけで20,000行のデータから価格予測を行う計算式を作れます。
では、配下のコードを実行してみましょう。以下のコードでは「model」という変数にモデルが格納されます。
# 説明変数と目的変数を分割します
X = df.drop('Target', axis=1)
y = df['Target']
# 学習データとテストデータに分割します
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBMのモデルを作成します
model = LGBMRegressor()
# モデルの学習を行います
model.fit(X_train, y_train)作成したモデルの評価
最後に作成したモデルの評価を行いましょう。前述のとおりテストデータを使ってモデルの評価を行います。まず、テストデータの価格情報以外のデータをモデルに投入し、predictという関数で価格情報の予測値を計算します。つまり家の大きさ、間取りなどから想定価格を算出するのです。その結果をy_predという変数に格納し、実際の価格情報(y_test)との差分を比較することでモデルを評価します。比較方法は以下の例ではrmse(2乗平方根誤差)と呼ばれる手法で評価します。要は実際の値と予測値の差を一つ一つ2乗(差はプラス、マイナスがあるので2乗します)して合計したものの平方根(2乗しているので元の尺度に戻す)を取ります。
以下のコードを実行しましょう。
# テストデータを用いて予測を行います
y_pred = model.predict(X_test)
# 予測結果の評価を行います(RMSE)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print('Root Mean Squared Error: ', rmse)そうすると誤差の結果がでます。
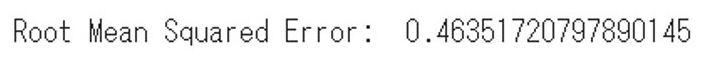
結果が0.46となりましたので今回のモデルの誤差は大体0.46(10万米ドル)くらい予測値と実際の差がでますよ、という結果と読み取れます。あとはこの誤差が許容できるかどうか、の判断はこのモデルの利用法などから考えていくことになります。これで物件情報だけでおおむねの価格が予測できるようになりましたので自動査定を行う、などができるようになるわけです。
おわりに
以上がGoogle Colaboratoryの基本的な使い方についてのガイドです。
無料のツールを使い、数十行のコードを書くだけでこんな高度な機械学習のモデルが作れるのはおどろきですよね!この情報が皆様のデータサイエンスに向けた成長に役立つことを願っています。是非、この便利なツールを使って、データサイエンスの世界を探索してみてください。
株式会社KUIXではこのような機械学習に関する開発案件の受託やデータ分析に関する教育、プロフェッショナル人材のご紹介などをお客様に提供しております。もし自社で進めるのはちょっと厳しい、といった場合は是非弊社までお問い合わせください!お問い合わせはこちらから











